
Are You Accidentally Blocking Valuable Links with robots.txt?

Dave Peiris
18 July 2024
Recently, I’ve noticed lots of ecommerce sites getting links from really strong sites, but then having that link value wiped out because they’ve accidentally prevented Googlebot from crawling the page. And it’s all to do with blocking parameters in robots.txt.
Here’s an example – Hotel Chocolat’s robots.txt file includes this instruction:

The Disallow: /*?* is designed to prevent Googlebot from crawling any URL that has a parameter. That means that URLs that include tracking parameters like utm_source or gclid (the Google Ads tracking parameter) won’t be crawlable.
But these URLs pick up links surprisingly often, and sometimes from really great sites. Here’s an article from The Guardian that links to Hotel Chocolat’s velvetiser page, using a ?gclid parameter.
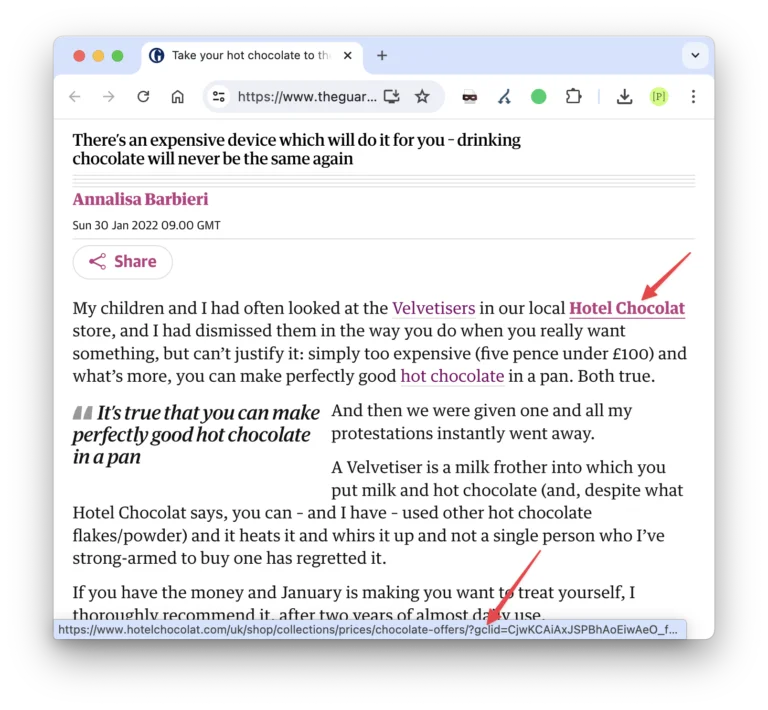
It’s likely the journalist Googled the name of the product while they were writing the story, and clicked on the first result they found—the paid ad.
Importantly, there can be really sensible reasons for engineering teams to make decisions like this – this isn’t necessarily a mistake. But the problem is the robots.txt file prevents Googlebot from crawling that linked URL. You can confirm that with the Structured Data Testing Tool (or Google Search Console if you have access – I should point out that Hotel Chocolat isn’t a client, so we don’t).
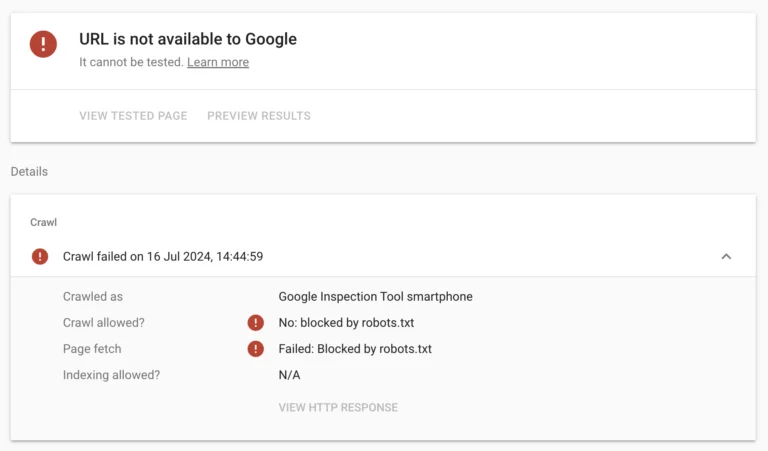
If Google can’t crawl the linked page, it’s effectively not part of the link graph and it won’t pass any link value into the site. That link from The Guardian would be really valuable, if only Googlebot could crawl the linked URL.
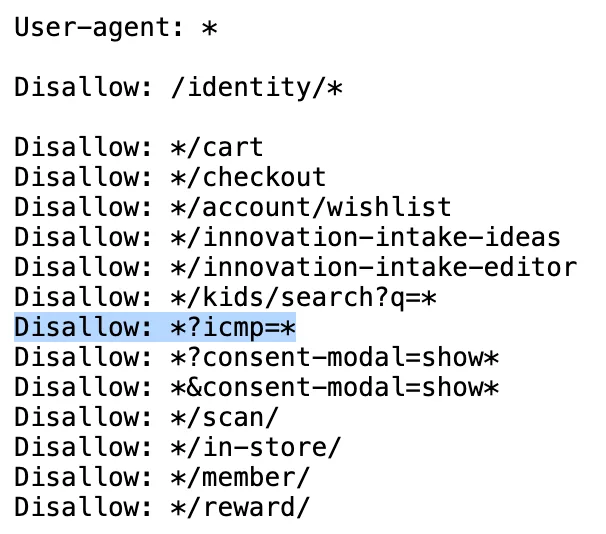
I see this pattern a lot, and even the very big players aren’t immune to it. Here’s an example with Lego.com’s robots.txt, where they’re blocking an ?icmp parameter from being crawled:
And here are some links from sites like Patreon, USA Today and Time that won’t be passing any link value as a result (and there are lots of others).
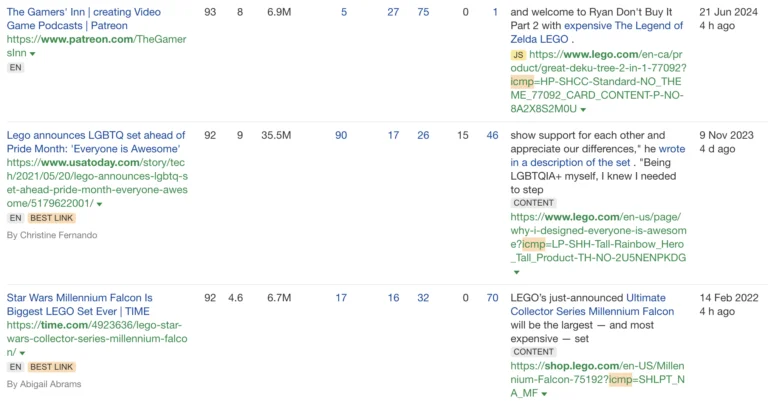
You can use Ahrefs to find these links
First, look in your robots.txt file and see if there are any parameters that are being blocked. If there are, you can use a tool like Ahrefs to see if they have picked up any external links. In the backlinks report, add your parameter and filter to “Target URL” (it should show you URLs that have that parameter in the link to the page). I tend to filter by followed links too.

You can fix this with canonical tags instead of using robots.txt
It’s worth having a chat with the engineering team about exactly why those parameters have been filtered. In most cases, I’d imagine it would simply be a pretty reasonable “we don’t want Google to index these URLs”. If that’s your situation, then my advice is to remove the directive in the robots.txt file, and instead make sure those pages all have canonical tags that reference the correct page, without the parameters.
That way Googlebot should index the correct version of the page, but the links to the parameter version will still be accessible and should flow to the canonical page.
Photo by Autumn Studio on Unsplash


