
Google’s Real Monopoly Is on the User data

Dave Peiris
6 August 2024
In a landmark case, a US judge has ruled that Google’s monopoly on search is unlawful.
Most news articles are reporting that Google have an unfair advantage because they pay Apple to be the default search engine on iOS. In Q1 of 2024, iOS had a market share of 28.5%, while Android—which also has Google as the default search engine—had a market share of 70.7%, according to Statista.
No, I also don’t know what the other 0.8% is.
But I think the real issue – which is partly related, but is also somehow separate – is that Google’s results are really good, and they’re really good because they have a monopoly on the user data.
Here’s a surprising fact: every single Google engineer could leave and all start a new search engine together, take the exact same source code for Google with them, and that search engine would be worse.
In business terms, Google has a moat–something that prevents rival businesses from copying them. Google’s moat is the fact that lots of people use them (there are 8.5 billion searches performed each day), and so they can collect a huge amount of data on user behaviour, and they can use that to refine and improve the quality of their results.
The US Department of Justice case revealed that Google was doing just that. Amongst lots of evidence, page 3 of this trial exhibit shows a slide from an internal Google presentation showing that their core ranking pillars are based on the document, links to the document, and user interactions with that document.
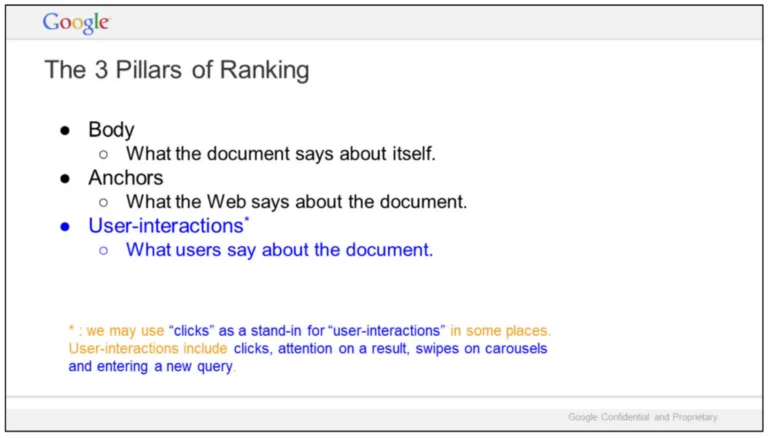
Leaked Google API documents also show that they’re collecting metrics on things like the number of clicks on search results, including measuring “good clicks” and “bad clicks”.
You can see it when you search for “gsvrnppl” (which is “facebook” if you accidentally press every key to the right of the one you meant to hit):
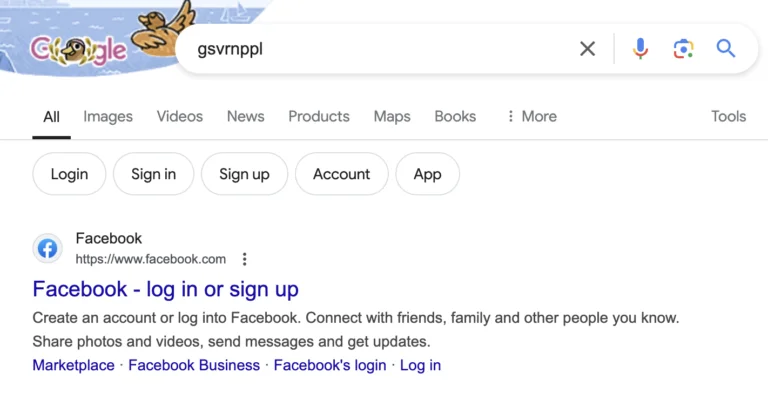
That’s directly as a result of users accidentally typing the wrong thing, refining their query to “facebook” and then clicking on that result. That user data has allowed Google to figure out that when people search for “gsvrnppl”, what they’re really looking for is Facebook. (h/t Mark Williams-Cook)
But that happens at enormous scale across every search – Google’s user behaviour data helps to refine and improve the quality of their search results. I don’t blame them for using it – personally I think it would be a mistake for them to not make use of such a large data set that can make your product better. And Bing, of course, does the exact same thing.
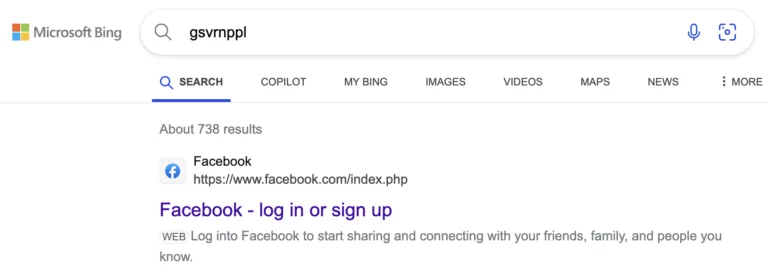
But the real question is, given that Google has around 90% of the search market share, and so has around 90% of the available user data, is the advantage it gives them so unfair that it should be illegal?


